UONTED – CLEI – CLEC – CLEGA
L’economia del futuro (che non ha un futuro)Archivio per Gaspari
Semantic Web: installazione di un sistema Debian per un progetto di web semantico
Ciao, dato che sulla distribuzione Debian testing l’installazione di Tomcat non andava mai a buon fine, ho reinstallato la versione stable ed ho preso qualche appunto. Per chi volesse installare un sistema Debian stable in vista dello sviluppo di un progetto di web semantico pubblico questi appunti che non vogliono essere una guida passo passo spiegata in ogni dettaglio, ma comunque una buona traccia che, almeno sul mio computer, funziona.
![]()
Come primo passo si deve installare Debian stable (detta anche Etch): download e masterizzazione dell’immagine, avvio da cd-rom e seguire le poche istruzioni e video.
Partizionare il disco fisso manualmente mettendo:
- partizione primaria inizio del disco da 100 Mb, file system ext3, montata come /boot
- partizione prmaria di swap pari al doppio della RAM, file system swap, usata come area di swap
- Eventuale partizione primaria per windows, file system ntfs, montata come /windows
- partizione primaria (se non c’è quella per windows, partizione estesa se c’è) grande il 90% dello spazio restante, file system ext3, montata come /home
- partizione estesa fino a riempire il disco, file system ext3, montata come /
Tutte le istruzioni vanno inserite in un terminale (una shell)
Configurazione SUDO
su (password) nano /etc/sudoers
aggiungere la riga:
nome-utente ALL=(ALL) ALL
Setup Repository Debian Stable
sudo nano /etc/apt/sources.list
inserire questo….
## Debian Stable (etch) deb http://ftp.it.debian.org/debian/ stable main contrib non-free #deb-src http://ftp.it.debian.org/debian/ stable main contrib non-free ## Aggiornamenti della sicurezza deb http://security.debian.org/ stable/updates main contrib #deb-src http://security.debian.org/ stable/updates main contrib
Salvare e aggiornare con:
sudo apt-get update sudo apt-get upgrade
Installazione Firmware Scheda Wireless
Con il comando lspci identificare il tipo di scheda wireless, e cercare il driver più appropriato. Io ho una Intel Pro Wireless 2100 per cui il mio driver si chiama ipw2100. Scarico da internet il firmware da sourceforge e lo installo:
sudo cp ipw2100-1.3.fw ipw2100-1.3-i.fw ipw2100-1.3-p.fw /usr/lib/hotplug/firmware sudo nano /etc/modprobe.d/aliases
Aggiungere le righe (in fondo):
alias wlan0 ipw2100 options ipw2100 ifname=wlan0
Editare /etc/network/interfaces
sudo nano /etc/network/interfaces
Aggiungere:
iface wlan0 inet dhcp pre-up modprobe ipw2100 ifname=wlan0 post-down rmmod ipw2100
Per attivare/disattivare l’interfaccia
ifup wlan0 ifdown wlan0
Installazione Flash Player
Scaricare il player Flash (http://www.adobe.com/shockwave/download/download.cgi?P1_Prod_Version=ShockwaveFlash)
tar xvfz install_flash_player_9_linux.tar.gz cd install_flash_player_9_linux/ sudo mv libflashplayer.so usr/lib/iceweasel/plugins/
Riavviare Iceweasel
Installazione Apache 2 e PHP
Guida (http://guide.debianizzati.org/index.php/LAMP:_Linux%2C_Apache%2C_MySQL_e_PHP#Apache_2.0)
sudo apt-get install apache2-mpm-prefork sudo apt-get install libapache2-mod-php4
Creare la cartella $home/public_html (nella quale mettere i file web) ed abilitarla con:
sudo a2enmod userdir sudo apache2ctl restart
I file saranno accessibili attraverso 127.0.0.1/~nome-utente/
Velocizzazione del disco fisso settando il DMA
sudo hdparm -d /dev/hda
Installazione di un ambiente di compilazione
sudo apt-get install doc-debian debian-policy make g++ gcc perl autoconf sed debmake devscripts fakeroot
Installazione di Java Development Kit
Download dal sito ufficiale del JAVA SDK versione 6, il binario jdk-6u6-linux-i586.bin
sudo apt-get install java-package
Qui c’è uno sbattimento da fare poichè Java-Package non è aggiornato con gli ultimi update del software SUN.
cd /usr/share/java-package/ sudo cp -a sun-j2sdk1.5 sun-j2sdk1.6 sudo gedit sun-j2sdk1.6/install
Sostituire la prima linea con: suffix=j2sdk1.6-sun
sudo gedit sun-j2sdk.sh
aggiungere:
"jdk-6u6-linux-i586.bin") j2se_version=1.6 j2se_expected_min_size=16 found=true ;;
Fine sbattimento
Da utente normale fai:
fakeroot make-jpkg jre-6u5-linux-i586.bin
Accetta il contratto, ecc…
Installiamo il pacchetto compilato (controlla il nome del file):
sudo dpkg -i sun-j2sdk1.6_1.6_i386.deb
Installazione di TOMCAT
sudo aptitude install tomcat5.5 tomcat5.5-admin tomcat5.5-webapps
Ferma il server
/etc/init.d/tomcat5.5 stop
Edita il file di configurazione:
sudo gedit /var/lib/tomcat5.5/conf/tomcat-users.xml
Inseriamo:
<?xml version='1.0' encoding='utf-8'?> <tomcat-users> <role rolename="admin"/> <role rolename="manager"/> <role rolename="tomcat"/> <user username="tomcat" password="47544" roles="tomcat,admin,manager"/> </tomcat-users>
Ripartire il server
/etc/init.d/tomcat5.5 start
Verifica se tutto funziona all’indirizzo http://localhost:8180/
Amministra al link http://localhost:8180/manager/html
Installazione di software utile
sudo apt-get install amule amsn vlc
Installazione dei driver NVIDIA (non quelli del sito Nvidia altrimenti ogni volta che cambia il kernel o che viene aggiornato xorg dà sempre errore e sono da reinstallare)
Installare:
sudo apt-get install module-assistant sudo m-a -i prepare sudo m-a a-i nvidia
Sostituire, nella sezione device, “nv” con “nvidia”
sudo gedit /etc/X11/xorg.conf
(questa parte è da rivedere)
Installare Skype
Download del file deb dal sito web
sudo apt-get install libqt4-core libqt4-gui sudo dpkg -i skype-debian_2.0.0.63-1_i386.deb (continua....)
Semantic Web Lezione 2
Numero di studenti a lezione: 2
Vediamo oggi un esempio di formalismo per rappresentare la conoscenza secondo la logica proposizionale. Il primo passo è definire la sintassi del formalismo, ovvero un insieme di formule atomiche (potenzialmente infinito) in genere limitato all’interno di un certo contesto. Il formalismo per indicare gli elementi di questo insieme sarà A, B, C, …., Ai
Definiamo dei connettivi logici AND, OR, NOT, ALLORA (implicazione)

Formule ben formate (FBF):
se 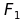 e
e 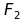 sono FBF allora
sono FBF allora 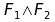 ,
,  ,
, ,
, sono FBF, formule ben formate.
sono FBF, formule ben formate.
La sintassi è legata al concetto di verità. Le asserzioni di base da cui partire sono in generale date come vere
La semantica
Un assegnamento è la specifica dei valori di verità per tutte le formule atomiche.
A = (Tutti gli uomini sono mortali) è vero (oppure valore 1)
B = (Socrate è un uomo) è vero (oppure valore 1)
Indichiamo con 1 il valore di verità, indichiamo con 0 la non-verità (logica binaria).
Altro esempio: sia A=1, B=0, C=1.
Dati i valori di verità, allora tutti i valori di verità prodotti dalle inferenze successive risultano automaticamente determinati. Cioè, se ho una regola che mostra come la verità si propaga mediante la connessione, ad esempio, di due formule atomiche, allora assegnando i valori iniziali di verità, essendo l’applicazione delle inferenze un puro processo meccanico, allora i risultati sono automaticamente determinati senza incertezze.
|
AND |
||
|
A |
B |
|
|
falsa |
falsa |
vera |
|
falsa |
vera |
falsa |
|
vera |
falsa |
falsa |
|
vera |
vera |
falsa |
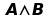
|
OR |
||
|
A |
B |
|
|
vera |
falsa |
vera |
|
vera |
vera |
vera |
|
falsa |
falsa |
falsa |
|
falsa |
vera |
vera |
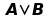
|
IMPLICAZIONE |
||
|
A |
B |
|
|
falsa |
falsa |
vera |
|
falsa |
vera |
vera |
|
vera |
falsa |
falsa |
|
vera |
vera |
vera |
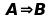
Posso generare delle formule che mi portino ad avere tutte le possibili combinazioni di zeri e uno? si… ad esempio per ottenere 1000 potrei avere 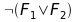
Alcune definizioni:
Def: Un modello per una formula T è un assegnamento che rende vera F.
Def: una FBF (formula ben formata) F si dice soddisfacibile se esiste un assegnamento che è un modello per F
E’ sempre possibile fare formule del genere?  è sempre falsa.
è sempre falsa.
Def: una FBF F è detta insoddisfacibile se non esiste un modello per F.
Def: una FBF F è valida se tutti gli assegnamenti sono modelli per F (tautologia). Le tautologie sono poco interessanti poiché qualcosa che è sempre e comunque vero non aiuta, non aggiunge molta conoscenza.
Def: due FBF e sono equivalenti se hanno stessi modelli (o se hanno la stessa tabella di verità). 
Alcuni esempi:

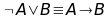
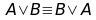
Leggi di De Morgan
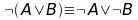
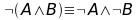
e ancora…
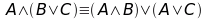
Le leggi di De Morgan mostrano come non tutti i connettori logici siano necessari, ma utilizzando solo OR e NOT riesco a rappresentare tutte le formule possibili.
Concetto della conseguenza logica: voglio sapere quali sono le formule ben formate che implichino la verità, che soddisfano la seguente relazione?
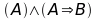
Una formula G (generica) è conseguenza logica di un insieme di formule F (formule in AND fra di loro) se per ogni assegnamento che è un modello per F allora questo è un modello anche per G.
Se per tutte le righe della tabelle di verità in cui F è vera anche G è vera, cioè ha lo stesso risultato, allora G è conseguenza logica di F.
Esempio.
Sia F una specifica di formule costituita da:



Come verifico se G è conseguenza logica di F?
Posso costruire tutte le righe della tabella di verità e le confronto con quelle di G.
|
A |
B |
|
|
B |
|
0 |
0 |
1 |
0 |
0 |
|
0 |
1 |
1 |
0 |
1 |
|
1 |
0 |
0 |
0 |
0 |
|
1 |
1 |
1 |
1 |
1 |
Sia G=B. B è conseguenza logica di F.
L’algoritmo che verifica la conseguenza logica ha complessità esponenziale.
Come si fanno le deduzioni?
Stabilisco un insieme di regole sulla base delle quali fare le deduzioni (regole di inferenza).
 Se nel mio insieme di formule ho formule che hanno questa struttura, ad esempio al posto di A e B posso avere anche altre formule più complesse, se ho la stessa struttura del modus ponens, allora posso aggiungere al mio insieme di conoscenza anche B, cioè B è vero. Questa deduzione deriva dalla regola di inferenza modus ponens.
Se nel mio insieme di formule ho formule che hanno questa struttura, ad esempio al posto di A e B posso avere anche altre formule più complesse, se ho la stessa struttura del modus ponens, allora posso aggiungere al mio insieme di conoscenza anche B, cioè B è vero. Questa deduzione deriva dalla regola di inferenza modus ponens.
Questo metodo deduttivo è corretto? E’ completo? Genero qualcosa che sia vero? Devo verificare che la regola di inferenza logica sia corretta. Dato che B è conseguenza logica diallora B è vera.
Non è possibile trovare la completezza di ….. (non ho capito)
Deduzione naturale
Creare un insieme di regole di inferenza che ….. ecc…
; 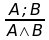 ; ….
; ….
Semantic Web Lezione 1
Info sul corso: Il corso quest’anno sarà più ridotto e concentrato nella prima parte del periodo di lezioni.
Libri di testo:
- The Semantic Web Primer (testo principale)
- Nilsson Nils I, Artificial intelligence a New Synthesis, Morgan Kaufmann 1998
- http://www.w3.org/2001/sw/
- http://www.semanticweb.org/
- http://www.semanticwebprimer.org/
Esame:
L’esame solitamente è composto da una prova scritta e da un orale, più un progetto da discutere durante l’orale. Dato che siamo in 3 studenti, il buon Gaspari propone di fondare l’esame solamente sul progetto (con frequenza delle lezioni).
Introduzione
“…odio fare cose che so benissimo che il computer potrebbe fare per me…”
Il web semantico non esiste ancora, ma ci si sta lavorando. L’ispirazione viene da una [visione] di Tim Berners-Lee.
Con il termine web semantico si intende la trasformazione del World Wide Web in un ambiente dove i documenti pubblicati (pagine HTML, file, immagini, e così via) siano associati ad informazioni e dati (metadati) che ne specifichino il contesto semantico in un formato adatto all’interrogazione, all’interpretazione e, più in generale, all’elaborazione automatica.
Internet ha visto una grandissima evoluzione dal 6 agosto 1991 quando Tim Berners-Lee pubblicò il primo sito web delle rete Internet. Era un’epoca in cui erano pochi i dati ed i materiali disponibili in rete, pochissima informazione era reperibile. Tutti coloro che volevano sviluppare applicazioni dovevano reperire informazioni fuori dalla rete. Oggi invece l’informazione viene messa a disposizione, spesso gratuitamente, con un grande grado di parallelismo: in ogni istante migliaia-milioni di persone stanno aggiungendo informazione e materiale di varia natura sul web.
Nonostante l’evoluzione tecnica ed i passi compiuti verso il web 2.0, il web rimane soprattutto una gigantesca biblioteca di pagine HTML. Lo standard HTML ha la grossa limitazione di occuparsi solo ed esclusivamente della formattazione dei documenti, tralasciando del tutto la struttura ed il significato del contenuto. Questo pone notevoli difficoltà nel reperimento e riutilizzo delle informazioni. E’ sufficiente eseguire una ricerca con Google per verificarlo: solo una piccola percentuale è d’interesse per la ricerca che s’intende fare.
Il motore di ricerca non distingue il significato delle parole: la parola “rosso” può essere un aggettivo (fiore rosso) come anche il nome di un colore (il rosso) o addirittura un cognome di persona ben definita (il signor Rosso).
Con l’interpretazione del contenuto dei documenti saranno possibili ricerche molto più evolute delle attuali, attraverso la costruzione di reti di relazioni e connessioni tra documenti secondo logiche più elaborate del semplice link ipertestuale.
Il web può essere visto come tre successive generazioni:
- Introduzione della tecnologia web (HTML), indipendente dalla piattaforma utilizzata, con un linguaggio di mark-up specializzato alla presentazione dei documenti. Interfacce uniformi e semplicità di accesso, bassa complessità (almeno lato client).
- Pagine costituite da template vuoti e contenuti generati al volo estratti da database, anche più di uno. Le tecnologie lato server creano dinamicamente le pagine HTML da presentare agli utenti sulla base di “regole” date da chi predispone l’applicazione che genera la pagina. Il web 2.0 dà la possibilità agli utenti di creare i contenuti e di collaborare per lo sviluppo di un progetto o di una comunità.
- Web Semantico: i contenuti sono processati e rielaborati automaticamente sulla base di regole date sia dal creatore delle applicazioni (motori semantici) sia dall’utilizzatore dei servizi.
Semantica
La semantica è quella parte della linguistica che studia il significato delle parole, degli insiemi delle parole, delle frasi e dei testi; è una scienza in stretto rapporto con altre discipline, come la semiologia, la logica, la psicologia, la teoria della comunicazione, la stilistica e la filosofia del linguaggio.
Sintassi
La sintassi è la branca della linguistica che studia le regole o le relazioni modulari che stabiliscono il posto che le parole occupano all’interno di una frase, come i sintagmi si compongano in frasi, e come le frasi si dispongano a formare un periodo.
Problemi con i motori di ricerca
I motori di ricerca restituiscono risultati basati su algoritmi molto complessi, ma basati sull’attuale modo di memorizzare l’informazione. Le informazioni sono oggi prevalentemente memorizzate secondo standard che non consentono di creare associazioni tra i simboli utilizzati come veicolo di informazione e la semantica da essi rappresentata. Non è possibile per un motore di ricerca riutilizzare e reinterpretare in modo automatico la conoscenza a cui ha accesso ma solamente tentare di classificarne la pertinenza rispetto alla domanda fatta secondo propri criteri.
Attualmente i motori di ricerca Internet restituiscono conoscenza: è compito dell’uomo capire e scartare ciò che non è pertinente, rielaborare e riassemblare le informazioni in funzione della specifica domanda.
Sia 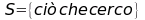 e sia
e sia  allora:
allora:
Definisco il fattore di  e vedo che è alto, poiché l’intersezione tra i due insiemi non è molto lontana da ciò che cerco, ovvero trovo quasi tutto quello che mi interessa.
e vedo che è alto, poiché l’intersezione tra i due insiemi non è molto lontana da ciò che cerco, ovvero trovo quasi tutto quello che mi interessa.
Definisco il fattore di  e vedo che è basso, poiché i risultati pertinenti e utili sono dispersi in un mare di altri risultati non pertinenti.
e vedo che è basso, poiché i risultati pertinenti e utili sono dispersi in un mare di altri risultati non pertinenti.
Ci sono sempre cose che cerco ma non trovo, ma ci sono moltissime più cose che non cercavo ma che mi vengono presentate come risultato.
Supponiamo di progettare un viaggio e di raccogliere informazioni a tale scopo:
- E’ più conveniente il treno o l’aereo, oppure l’auto? E’ necessario fare diverse ricerche sui costi, sui percorsi, le distanze, le tappe da effettuare, gli orari dei trasporti pubblici e privati. Se si usa l’aereo, dove si atterra, come è il collegamento tra l’areoporto e la città, i costi collegati agli spostamenti.
- orari, combinazioni, prezzi, ecc.. Si tratta di un problema di minimo, trovare la soluzione migliore sotto certi vincoli.
- Un AGENTE, un programma automatico, potrebbe aggregare e rielaborare la conoscenza che è già pubblicata e reperibile online e presentare dei risultati.
- Purtroppo adesso i dati non sono strutturati per essere reinterpretati da un agente raccoglitore di informazioni.
- Per poter realizzare questo tipo di rielaborazioni sono necessarie delle trasformazioni della struttura che memorizza l’informazione.
Cosa potrebbero fare i motori di ricerca? Potrebbero ricercare concetti invece che keyword. Che cos’è un concetto?
Immaginiamo una pagina scritta in giapponese: non capiamo nulla, ma se ci viene indicato che la prima riga è il nome della persona, che si tratta di un curriculum vitae, che il primo paragrafo parla della educazione della persona, che il secondo elenca le esperienze lavorative, ecc…. Allora, anche se ancora non conosciamo il giapponese, siamo già in grado di capire almeno di che tipo di documento è, se è di interesse e come classificarlo.
HTML E XML
L’HTML è un linguaggio di mark up applicato alla presentazione del testo.
Per la costruzione del web semantico si utilizza l’XML, un linguaggio che consente di descrivere semanticamente le diverse parti di un documento. Con l’XML è possibile descrivere adeguatamente i contenuti di un documento ma la sintassi XML non definisce alcun meccanismo per realizzare le relazioni tra i documenti. Il meccanismo dei collegamenti ipertestuali HTML è inutile poiché non prevede la possibilità di descrivere il legame definito.
Se in un documento parlo di MARIO ROSSI è poi difficile capire se due documenti che parlano di Mario Rossi e si riferiscono alla stessa persona fisica o a due differenti, con conseguente scarsa qualità dei risultati restituiti dai motore di ricerca.
XML dà infatti una descrizione, mediante i tag, del contenuto dei tag stessi. Ad esempio:
<course> <title> introduction to AI </title> <teacher> Mauro Gaspari </teacher> <students>Giovanni Gardini</students> </course>
L’XML descrive come è strutturato questo piccolo albero di informazione ed esprime una modalità per esprimere contenuti. Ogni nodo ha una etichetta, degli attributi ed il suo contenuto.
XML e’ un notevole miglioramento rispetto a HTML, ma non consente di rappresentare la semantica. XML e’ un modo efficace memorizzare e condividere le informazioni, ma non dà certezza circa il reale significato di ciò che sto comunicando. XML realizza degli schemi, ma non indica differenze semantiche, o le indica anche se non vi sono.
Consideriamo le due seguenti frasi:
“Il corso di web semantico è tenuto da Mauro Gaspari.”
“Mauro Gaspari tiene il corso di web semantico.”
In XML la rappresentazione dei due concetti è diversa (si inverte soggetto e predicato). Tuttavia la semantica dei due concetti è la stessa, c’è lo stesso significato. Per noi questo tipo di inferenze sono automatiche, ma è possibile renderle accessibili anche ad una macchina? È questo lo scopo del web semantico. Una volta completato, sarà possibile «interrogare» il web su quello che «sa» riguardo certe risorse, non facendo una query su un singolo database o su una directory, ma ricercando nell’intero web semantico, che dovrebbe fare da collante per tutte le basi di dati locali, un po’ come fa l’attuale web, ma aggiungendo significato alle semplici stringhe di caratteri.
XML è dunque alla base del web semantico, e provvede a dare una rappresentazione dei dati. Altri strati successivi si occupano di creare relazioni.
LINGUAGGIO
- SINTASSI
- SEMANTICA
- MECCANISMO DEDUTTIVO
All’interno di una pagina web ho delle entità che dichiarano dei concetti. Ad esempio utilizzo la notazione NOME(Mauro) per dichiarare che esiste una classe che si chiama NOME e che esiste un oggetto di quella classe che si chiama Mauro. Nel momento in cui dichiaro l’esistenza di qualcosa, questa cosa si assume associata al concetto di verità.
NOME(Mauro) è vero.
UOMO(Mauro) è vero.
MORTALE(UOMO) è vero
Sillogismi alla Socrate
UOMO(X) => MORTALE(X)
Attraverso le regole sintattiche che vedremo (logica) elaboreremo la conoscenza che noi descriviamo attraverso le entità che dichiareremo. Queste regole forniscono un modo per trasferire la verità attraverso i concetti dichiarati. Sono modi per calcolare la verità e collegare la conoscenza, meccanismi deduttivi che un programma utilizza per calcolare relazioni tra conoscenze.
Motore inferenziale
Partendo dall’insieme di regole date, dalle regole inferenziali, si ottengono risultati calcolando attraverso la logica dei predicati.
Ad esempio il MODUS PONENS
se A, A=>B se ho A, se so che A implica B, allora B.
Il motore di meccanismo deduttivo usa le regole a disposizione per calcolare la verità del predicato B. Attraverso una serie finita di passi supponiamo di arrivare a ciò che ci interessa, al nostro GOAL, il nostro obiettivo. Se il meccanismo deduttivo, partendo da cose vere e attraverso una catena di inferenze logiche corrette, arriva al goal, cioè a risultati giusti, attraverso un percorso detto CORRETTO.
Se il meccanismo deduttivo trova tutti i risultati giusti, allora è detto COMPLETO.
I meccanismi deduttivi sono spesso già implementati, per cui il lavoro che ci spetta sarà definire correttamente la conoscenza e fare dei buoni formalismi. Sarà difficile trovare un buon bilanciamento tra espressività ed efficienza: a volta la complessità del meccanismo deduttivo è esponenziale e dovremo tenere conto anche di altre proprietà come decidibilità, non decidibilità.
Consiglio di Facoltà

- La dott.ssa Silvia Pazzi è la nuova tutor del CLEI: a lei possiamo rivolgerci per domande, consigli, ecc.. (silvia.pazzi@unibo.it).
- Alla richiesta di mantenimento delle attività di laboratorio per le materie informatiche, le più ostiche a quanto pare, si è deliberato di richiedere al consiglio di facoltà (ad Economia quindi) l’attivazione di un tutorato che sia di supporto agli studenti per le materie informatiche che richiedono la preparazione di un elaborato (i progetti). Questo tutorato sarebbe per quest’anno mirato agli esami di fondamenti di programmazione e laboratorio di programmazione, gli anni successivi includerebbe anche gli ulteriori esami via via disattivati.
Il prof Gaspari si è reso disponibile inoltre per far sostenere gli esami agli studenti in debito di fondamenti di programmazione e di laboratorio di programmazione (a condizione che sia attivato il tutor).- Commento: se non ricordo male (si, lo so, avrei dovuto scrivere questo post appena dopo la riunione e non un mese dopo) esiste davvero il problema di chi ti fa sostenere l’esame che hai lasciato indietro. Per i corsi disattivati non esiste più la possibilità di dare l’esame in via Pratella, o in facoltà, nei modi in cui siamo abituati, ma sarà indicato, di anno in anno, il professore a cui rivolgerci: sarà scelto, immagino, in base al fatto che insegna la stessa materia da un’altra parte, magari a cesena o a forlì stessa, ma probabilmente con un programma differente dal nostro e non è tenuto ad adattare la prova d’esame al programma che abbiamo svolto noi. Per cui affrettiamoci!! Nel caso specifico del prof Gaspari, se non si offrisse lui dovremmo sostenere l’esame con un altro professore, magari di Scienze dell’Informazione di Cesena!
- La laurea magistrale “ECONOMIA E GESTIONE AZIENDALE – percorso IMPRENDITORIALITA’ E INNOVAZIONE” – che a breve sarà presentata ed approvata – ha un problema per chi proviene dal CLEI: diversi esami che essa prevede come propedeutici, tipici del CLEGA ad esempio, costituiscono un debito formativo da sanare. Ci sono cioè alcuni esami da aggiungere al quelli della laurea magistrale. Per contro, esistono alcuni esami di natura informatica che saranno proposti nella magistrale: questi esami sono pensati (anche) per coloro che provengono da corsi esclusivamente economici. Il livello sarà basso quindi, basso inteso nel senso che chi viene dal CLEI avrà già fatto tutto, anzi si spera molto di più di ciò che sarà proposto in questi corsi.
In sede di consiglio si è deliberato di predisporre una modulistica e una serie di suggerimenti costituenti un percorso facilitato per gli studenti CLEI – sfruttando la possibilità offerta dall’Ateneo di Bologna di presentare un piano degli studi personalizzato – mediante il quale consentire l’eliminazione degli esami informatici e l’introduzione di quelli a debito. In questo modo il numero degli esami dovrebbe essere grosso modo lo stesso previsto dalla magistrale.- Commento: questa magica soluzione l’ho proposta io. Dubito che usufruirò, penso di fermarmi e seguire altri progetti, però voi fatelo, così a naso questa magistrale sembra interessante.
- Soppressione delle discussioni di laurea: a fronte di alcuni problemi, tipo recuperare sufficienti professori per costituire la commissione e numero sempre più esiguo di studenti per ciascuna sessione, si è deliberato di proporre l’abolizione della discussione della tesina, ma solo a partire dall’anno 2008/2009, poiché per regolamento didattico del CLEI si è già approvato di continuare con il vecchio modus operandi anche per quest’anno.
- Commento: come cambieranno le cose? Il relatore presenterà la tesi alla commissione di laurea, la quale esprimerà una valutazione e successivamente avverrà la proclamazione. La discussione davanti al pubblico sarà eliminata: questo, per me e non solo, sarà un vero peccato, ma così sarà.
- Saranno sensibilizzati i docenti per una pubblicazione più agile dei materiali didattici.
- Gli appelli parziali talora non sono concessi ai fuori corso: i docenti devono dare la possibilità ai fuori corso (come anche ai non frequentanti) di sostenere gli esami parziali.
- Commento: se sei fuori corso e il prof ti nega la possibilità di fare l’esame, pretendi di poterlo fare e cita il verbale l’ultima seduta del consiglio di corso di laurea. Alla peggio chiama la Francesca Ruffilli!!!
Ragazzi, è fondamentale finire il prima possibile, non so se mi spiego…





